
This is a post I wish existed before going on this journey. I have been playing with the idea of using a state management library for Angular apps for a while now. I never really got to it, as the barrier to entry seemed relatively high, and most of my projects did not require such complexity. The costs outweigh the benefits, although I wasn’t sure. Now is the time to start digging into this. And I did, so if you are in a similar situation, this post will save you a lot of time.
A quick look at the landscape yielded NgRx and NGXS. I read the docs. Yes, all of it. If done right, this is surprisingly fast and efficient. This will be another post sometime. I prefer to base my decisions on data and experience, so I wanted an in-depth comparison of the two libraries. Surprisingly, I failed to find one that answered my questions 🤨 Hence this post.
Don’t get me wrong, there are many comparisons, but I couldn’t easily find one that goes beyond the “boilerplate issue” and the difference in syntax. Nobody likes boilerplate, and yes, better syntax is more pleasurable to look at. And yet, in 2023 when code can be generated by AI copilots and IDEs, boilerplate isn’t much of a problem. As for reading boilerplate, if you know the paradigm, you know exactly where and what to look for. Also, do not mistake boilerplate for explicitness. True boilerplate can be quickly abstracted away, usually done by the library maintainers. NgRx is explicit, very much so.
Anyway, since I couldn’t find what I was looking for, I started building it. I like to do my own thinking anyway.
Here is the spoiler. I started with NGXS and turned to NgRx. While working with NGXS, a few things kept lurking in my mind in the form of questions. The more I pondered, the more I turned to NgRx, and finally, I decided to use it instead. This might surprise you as most posts go the other way around. I offer you a different perspective and hope to aid you in choosing wisely. I am not advocating for either library but just laying out my thoughts and reasoning. Both are perfectly capable of solving complex problems cleanly. However, cleanliness is defined differently between them.
By the end of the post, you should have a good idea of which library would fit your needs. I would have been grateful if someone wrote this up before me 😃
The rest of the post assumes you understand the two frameworks well. If not, it’s a good idea to skim through both websites. Although there are some things I consider crucial, and they don’t get as much emphasis in the docs 🤨
Why state management?
First things first. Why on earth would you start working with state management when you have BehaviorSubject and RxJS? To appreciate the value proposition of such a library, you have to have had the problems it solves. State spilled over your front-end code, irreproducible bugs, and crazy complex test choreographs. Using state management libraries is a tradeoff, one that has its costs, which you may not be ready to pay yet. Nobody cares about pure functions until they see the power and cleanness of immutability. And let’s be honest, some that experience functional programming never want to go near it ever again 😅
For me, the value is in the underlying principles:
- Separate events from handlers
- This forces you to think very carefully about your features.
- Pure functions as state reducers
- Functional programming is a competent technique; everyone would benefit from knowing more.
- Clean & easily testable
- Testing must be a first-class citizen; with state management paradigms, it becomes second nature.
There is value in having a single way to do something and adhering to collection of strict best practices. While syntax and less boilerplate are pleasant, they’re not on my fundamental principles list.
NgRx
NgRx is a framework for building reactive applications in Angular. NgRx provides libraries for managing global and local states, isolation of side effects to promote a cleaner component architecture, entity collection management, integration with the Angular Router, and developer tooling that enhances developer experience when building many applications.
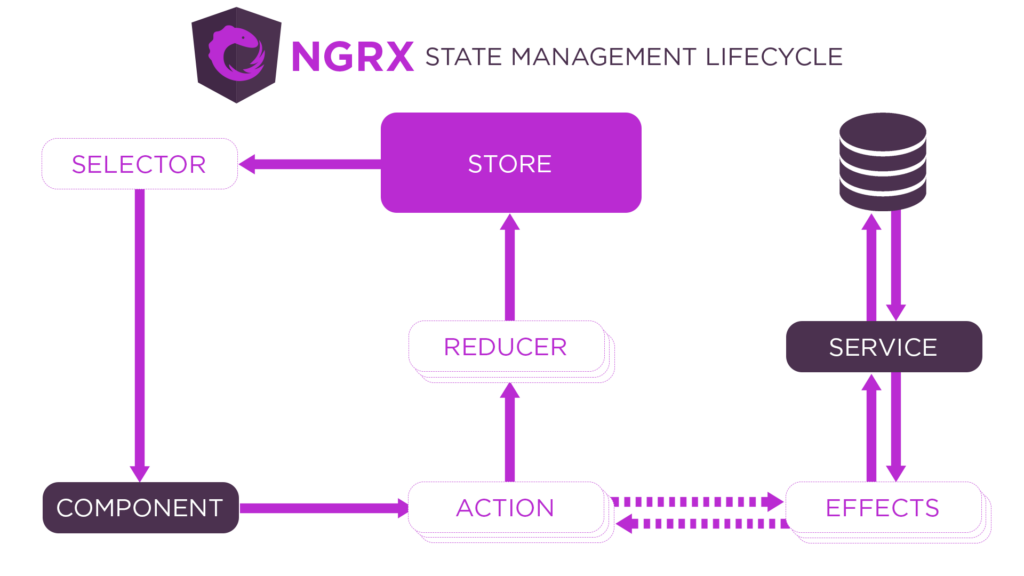
Key concepts
- Actions describe unique events that are dispatched from components and services
- State changes are handled by pure functions called reducers that take the current and latest actions to compute a new state.
- Selectors are pure functions used to select, derive, and compose pieces of state.
- State is accessed with the Store, an observable of state and an observer of actions.
- Effects are an RxJS powered side effect model for Store. Effects use streams to provide new sources of actions to reduce state based on external interactions such as network requests, web socket messages, and time-based events.
All of the above is from the NgRx website. NgRx prescribes an architecture for you. If you design your app around this, it will serve you well. However, if you do not like the architecture it provides, you will have a hard time working with this framework.
NGXS
NGXS is a state management pattern + library for Angular. It is a single source of truth for your application’s state, providing simple rules for predictable state mutations.
NGXS is modeled after the CQRS pattern popularly implemented in libraries like Redux and NgRx but reduces boilerplate by using modern TypeScript features such as classes and decorators.
Two interesting parts here:
- NGXS is a state management pattern
- It is modeled after the CQRS pattern in Redux and NgRx
NGXS introduces a pattern similar to Redux and NgRx, but there are fundamental differences. Getting a good grasp of these is essential to base your decision on more than just syntax and less boilerplate.
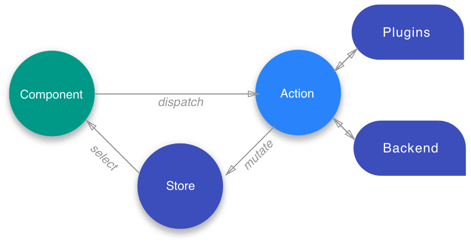
Key concepts
- Store: Global state container, action dispatcher and selector
- Actions: Class describing the action to take and its associated metadata
- State: Class definition of the state
- Selects: State slice selectors
There is no mention of reducers or effects, and for good reason. You might have seen this formula before:
NgRx reducers + NgRx effects ~ NGXS state
NGXS takes a more liberal approach and provides you with various options. There are multiple ways to achieve the same thing. Depending on your use case, some methods are preferred. It can make your life easier. You must choose carefully and bear the consequences.
Best practices
While working with state management, I was desperate to find a collection of best practices similar to Redux’s. The NgRx and NGXS docs provide hints here and there but no definite guides.
Most of it is “Here is Feature X you can use to do Y”. Questions like these are unanswered:
- should I even do Y?
- what are my alternatives to doing Y?
- why should I use Feature X over an alternative?
- how would this look without Feature X?
- what are the principles behind Feature X?
For some of these, you can find hints in the docs or by reading the code. I am not saying these answers do not exist, but finding them is hard. Seasoned front-end developers probably know these by heart. I haven’t yet mastered front-end, so I stuck with the Redux style guide mentioned earlier.
And that’s when things started to get interesting. NgRx follows these rules and recommendations, while NGXS encourages violations of the rules defined in the style guide. Do keep in mind that NGXS never claimed to adhere to these (nor should it), and it clearly states it is a state management pattern on its own (a different one from Redux or NgRx), only being modeled after Redux. In essence, NGXS took pieces from Redux and NgRx, introduced new concepts, and altered some existing ones.
Why does using the Redux style guide to evaluate NGXS and NgRx make sense? It boils down to the principles. I wanted to understand how both frameworks approached the ideas described and see how and why they deviate. I was sure there were tradeoffs, but I didn’t know what these were.
A good starting point is checking out a few places where NGXS is at odds with the Redux world. Note that NgRx follows these very closely.
Model Actions as Events, Not Setters
I start with this as this is the root source of most differences.
Here is what NGXS docs say about Actions.
Actions can either be thought of as a command, which should trigger something to happen, or as the resulting event of something that has already happened.
The Redux style guide clearly states that Actions should be events and NOT commands. On the other hand, NGXS defines them as commands or events. This will make sense as you read on. Working with commands has many benefits.
Commands are actions that tell your app to do something. They are usually triggered by user events such as clicking a button or selecting something.
Keep this in mind as you read through the rest of the post. See if you can deduce the different design choices to this fundamental difference.
Reducers Must Not Have Side Effects
This is the second rule after the do not mutate state. It says a reducer must not do anything other than calculate the next state. Notably, no AJAX calls, no timeouts, no promise handling, etc. All those should be handled separately, not in reducers.
NGXS does not have reducers, the closest you can think of is the handlers within the State. Take this code from the NGXS docs.
@State<ZooStateModel>({
name: 'zoo',
defaults: {
feedAnimals: []
}
})
@Injectable()
export class ZooState {
constructor(private animalService: AnimalService) {}
@Action(FeedAnimals)
async feedAnimals(ctx: StateContext<ZooStateModel>, action: FeedAnimals) {
const result = await this.animalService.feed(action.animalsToFeed);
const state = ctx.getState();
ctx.setState({
...state,
feedAnimals: [...state.feedAnimals, result]
});
}
}
Having AJAX calls, as you see in feedAnimals with await this.animalService.feed(action.animalsToFeed); is a primary use-case in NGXS. Writing it otherwise would be very hard. The syntax and the API both nudge you in this direction. And it feels natural.
Action comes in, you set a loading state, start an async call, and once it returns, set a loaded state and populate the store with the received data. All in a few lines of code, very close to each other. Looks lovely!
@Action(LoadData)
loadData(ctx: StateContext<StateModel>, action: LoadData) {
ctx.patchState({ state: StateEnum.Loading });
this.dataService
.loadData(action.dataId)
.pipe(tap((res) => ctx.patchState({ state: StateEnum.DataLoaded, data: res.data })));
}
You pay for this simplicity elsewhere. How would you test this?
Approach 1 – Test the whole command
Assume this is in a describe('LoadData action') block.
it('should change state enum to Loading, call DataService then set state to Loaded and populate store with data', () => {
store.dispatch(new LoadData(1));
expect(store.selectSnapshot<StateEnum>(state => state.state))
.toBe(StateEnum.Loading);
loadSubject.next({ data: 'some data' });
expect(dataService.loadData).toHaveBeenCalledWith(1);
expect(store.selectSnapshot<StateEnum>(state => state.state))
.toBe(StateEnum.Loaded);
expect(store.selectSnapshot<string>(state => state.data))
.toBe('some data');
});
This is messy, as you can see from the test name. There are lots of “ands” in there. Of course, you could abstract this and say something like “should populate data from DataService while correctly updating loading states”. This is also a bit rigid regarding how the implementation looks; you prescribe a specific order of calls. It also deviates a bit from the typical Arrange, Act, and Assert flow as we have an authSubject.next() call in the middle. It’s nothing wrong, but it is not how I like to write tests.
Approach 2 – Split up test cases
it('should change state to Loading', () => {
store.dispatch(new LoadData(1));
expect(store.selectSnapshot<StateEnum>(state => state.state))
.toBe(StateEnum.Loading);
});
it('should call DataService with correct id', () => {
store.dispatch(new LoadData(1));
expect(dataService.loadData).toHaveBeenCalledWith(1);
});
it('should finish with state as Loaded and store populated', () => {
store.dispatch(new LoadData(1));
loadSubject.next({ data: 'some data' });
expect(store.selectSnapshot<StateEnum>(state => state.state))
.toBe(StateEnum.Loaded);
expect(store.selectSnapshot<string>(state => state.data))
.toBe('some data');
});
This is excellent in terms of test size and complexity. It is similar to how you would approach this with NgRx; however, it fragments your logic into smaller pieces. It also feels a bit uneasy to have the same Act phase, yet Assert different requirements. That’s very different in NgRx, where each Act is tied to an expected action (some of it is a reducer function, while others are written in effects). If you go down this route, it might also induce some questions. For instance, if I am only testing a small part of this, couldn’t that be self-contained? Where is the limit to putting logic into such a handler? With two state changes, it is relatively trivial, but what makes you stop at two?
I’ll leave the answers with you 🙃
These same tests in NgRx would look like this.
describe('Reducer', () => {
describe('loadData action', () => {
it('should set state to Loading', () => {
const action = Actions.loadData({ id: 1 });
const newState = reducer(initialState, action);
expect(newState.state).toBe(StateEnum.Loading);
});
});
describe('loadDataSucceeded action', () => {
it('should set state to Loaded and populate store', () => {
const modifiedState = { ...initialState, state: StateEnum.Loading };
const action = Actions.loadDataSucceeded({ data: 'some data' });
const newState = reducer(modifiedState, action);
expect(newState.state).toBe(StateEnum.Loaded);
expect(newState.data).toBe('some data');
});
});
});
describe('Effects', () => {
// actions$ is a ReplaySubject
it('dispatches loadDataSucceeded on successful api call', () => {
const source = Actions.loadData({ id: 1 });
const completion = Actions.loadDataSucceeded({ data: 'some data' });
actions$.next(source);
dataService.loadData.and.returnValue(of({ data: 'some data' }));
effects.loadData$.subscribe(result => {
expect(result).toEqual(completion);
expect(dataService.loadData).toHaveBeenCalledWith(1);
});
});
You can see the same patterns here more explicitly. The two reducers are parallel to the patchState calls from NGXS, and the effect test is the async API call. What is remarkable here is the reduced Angular dependency; we don’t need a TestBed at all; we can test all of these without touching Angular. Pure functions are straightforward to test because they don’t have side effects. Side effects are also easy to test because they are isolated into small units.
Side-effect summary
While NgRx is very strict, NGXS is taking a more flexible approach. Instead of dissecting the above flow into multiple Actions and “sprinkling” this logic over Reducers and Effects it keeps it in one place. It looks great on the code side but makes testing more complicated and could raise further questions. An understandable tradeoff.
Are you happy to live with that?
Put as Much Logic as Possible in Reducers
The idea behind this rule is that Reducers are very simple to test. As we have seen, that’s not inherently true of NGXS’ States, because of the side-effects. A naive translation of this rule would call for as much logic in States as possible. And that’s a good idea, but it can quickly become too extensive without splitting a flow into multiple Reducers. Of course, you always have the choice of breaking your flow into multiple Actions, but in my opinion, that must be driven by the domain and not the underlying technology’s implementation detail.
The Store‘s dispatch() method in NGXS returns an Observable (more on this later). The API practically invites you to build logic upon this in your components and other handler methods. It’s ok, sometimes this makes our job a lot easier.
store.dispatch(new Login()).subscribe(() => this.form.clear())
The above can become very handy. While it is very convenient, it could quickly become a slippery slope.
NgRx adheres to this principle 100%. NGXS is also very close; however, some design choices prefer convenience over strict rules, making it harder to follow this practice.
Again, this is a tradeoff, preferring usability and convenience over common patterns.
You should start feeling the differences between the approaches and might also have a candidate in mind for your next project. Let’s dive deeper and see a bit more details.
Different perspectives
NGXS takes a slightly different approach compared to classic state management like NgRx. It may look the same, but it is unique. In this section, we’ll dive into the how and their implications. I’ll share my thoughts and conclusions. We’ll be comparing NgRx to NGXS.
Commands, events and actions
I implemented a magic link login flow using both libraries during my journey. Here is the basic flow.
- The user arrives on site, enters email in a form
- The user clicks the “Send me a link” button
- A magic link is sent to the user via email (by the backend)
- The user opens the magic link
- The token at the end of the link is checked for validity (by the backend)
- If valid, the session is initialized, and the user is redirected to a dashboard
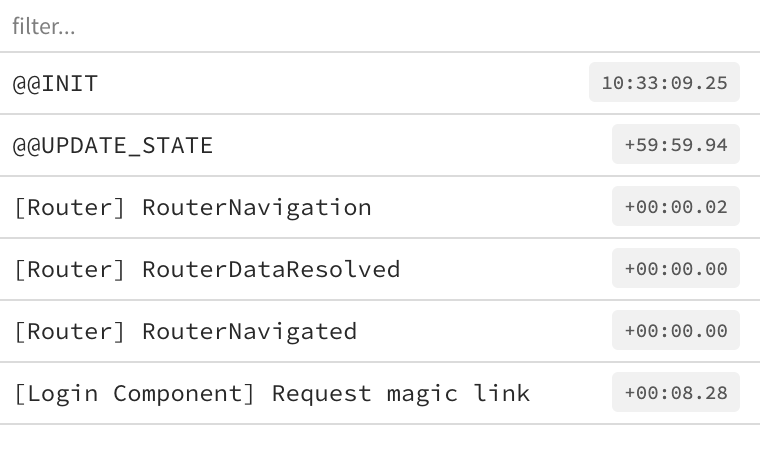
For this, in NGXS, I only needed 2 commands:
[Login Component] Request Magic Link[Magic Link Login Component] Login with token.
In NgRx this took 6 events:
[Login Page] Request Magic Link[Auth API] Magic Link Request Succeeded[Auth API] Magic Link Request Failed[Magic Link Login Page] Authenticate[Auth API] Authentication Succeeded[Auth API] Authentication Failed
NgRx requires lots of code and provides greater visibility and smaller pieces. In NGXS, the DevTool only shows the single command for the first part of our use case.
NgRx correspondingly shows two actions.
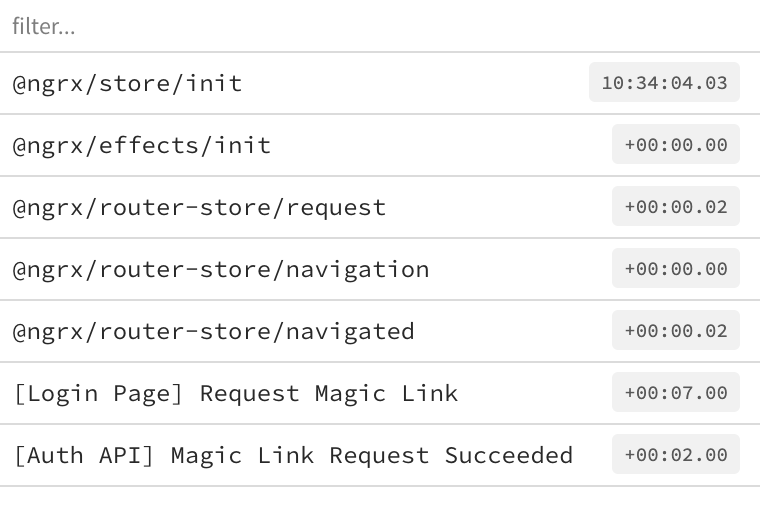
If you don’t split actions, testing becomes more complicated, and your debugging life becomes more challenging. You lose visibility into what’s happening in the app. Remember the earlier example of loading data. Let’s see how that looks as a command and as an event.
NGXS command
Here is what it looks like Command style in NGXS.
@Action(LoadData)
loadData(ctx: StateContext<StateModel>, action: LoadData) {
ctx.patchState({ state: StateEnum.Loading });
this.dataService
.loadData(action.dataId)
.pipe(tap((res) => ctx.patchState({ state: StateEnum.DataLoaded, data: res.data })));
}
Notice the multiple state changes with patchState and the async service call with loadData. The first state change is invisible in dev tools as the next overshadows it. No time travel for the loading state. It is also hidden in the logs. The below examples are from the magic link login use case. The state equals the portal.auth.state parameter, and there is no data load. For our purposes, it’s fine.
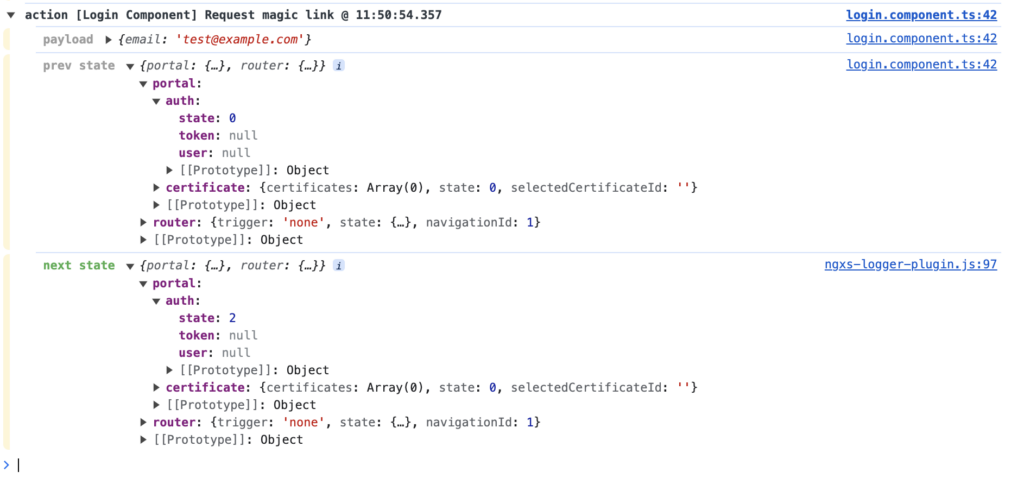
There is actually a hidden state change. When the request starts, I mark it with state.portal.auth.state = 1 to show a loading indicator. This is completely missing from DevTools and the logger as well.
NgRx event
The same using Event style with NgRx is more lengthy and complex.
// load data effect
createEffect(() => {
return this.actions$.pipe(
ofType(loadDataRequest),
switchMap(({ dataId }) =>
this.dataService.loadData(dataId).pipe(
map((res) => dataLoadSucceeded({ data: res.data }))
)
)
);
});
createReducer(
{ state: "StateEnum.NotLoaded", data: "" },
on(loadDataRequest, (state) => {
return { ...state, ...{ state: "StateEnum.Loading" } }
}),
on(dataLoadSucceeded, (state, { token }) => {
return { ...state, ...{ state: "StateEnum.Loaded", data: token } }
}),
);
As you can see, the NgRx code is broken into 3 distinct parts: 2 reducers and an effect. All state changes are clearly visible in DevTools and logs and time travel debugging is possible between them.
Notice the switchMap operator and the lack of it in NGXS; we’ll get back to that.
Commands versus events
These look very similar on the surface but are quite different.
When you issue a command, you expect a particular outcome. In fact, that’s precisely what you want. The Login command must end with the user being logged in. It prescribes a flow of things that must happen for the command to run successfully. It is like calling a function. A command can succeed, fail, or get canceled while executed. Hence, the Action lifecycle in NGXS (more on it later). When you issue commands, you want to know their status, and NGXS does that beautifully.
On the other hand, when you work with events, you do not know who, if anyone, is listening to that event. There is no point in an event having failed or succeeded as it is only dispatched. Whoever handles it can do so as they wish. You can’t get any information about what happened to the event as that is, according to the pattern, none of your business. Your responsibility ends with dispatching the event. This is NgRx, Redux style. You can do custom acknowledgments in your actions to get back information, but you have to do so explicitly.
An example is in order.
When you dispatch a Login command, you instruct the rest of the application to do something. You are in control of what that something should be. You do not control the how, but the flow specification is yours. When dispatching a command like this, you want to know the result of the command. Again, you can’t get information about what happened, but the fact that it succeeded or failed is exposed to you. You can dispatch further messages and update the UI based on the command’s execution. This is what NGXS provides for you. When using commands, we usually implement the entire flow (reducers, effects) as a State handler method.
When you dispatch a Login event, you only care about the fact that it happened. You could call it Login button clicked. We don’t do that, as it would add too much detail to the action’s name and make our design more rigid. This is more of an announcement of intent. As the dispatcher, you are not in control of what will happen. Another independent effect will likely pick up this event and start the login process. Again, you don’t know what’s happening behind the scenes; you only see the state updates, like “Login in progress”, “2FA required”, “Login succeeded”, etc. Your component, or an effect, probably listens to a “Login succeeded” action and handles it. The action initiator and its handler are separated and exchange information using the action. In NgRx, the login flow is implied, but the parts of it are explicit. You have no way of seeing the whole flow. You need multiple reducers and effects for the login flow to execute. This can be accomplished with a few lines of code in NGXS.
Using events, you must decouple producers from consumers (reducers, effects, and components). This is the style that NgRx promotes, and this is the cause of the “boilerplate” you see around you. Conversely, NGXS takes its own approach, focusing on usability and convenience. It does not force you to strictly separate producers and consumers. You can do multiple state changes using a single State method and dispatch further actions. This is very powerful. While NGXS doesn’t force a clear separation, it makes it possible.
It is up to you to decide how you want to model your problem domain. NGXS gives you freedom and responsibility.
Action lifecycle
Since NGXS works with actions as commands, having a lifecycle for these makes sense. There is no such thing with NgRx, as actions are pure events. This boils down to the Command versus Event section we discussed earlier. Here, I want to note a few key things. You can read more about the details in the NGXS docs.
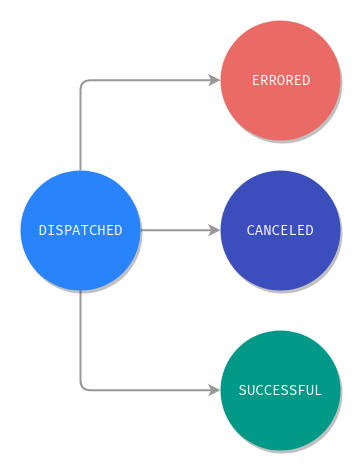
The returned Observable
Remember the returned observable from dispatch? That’s bound to the action’s lifecycle. You can react to what happened to the action. This is referred to as “fire and wait”, as in dispatch the action and do something upon completion. There is also a “fire and forget” method, which does not care about the action’s lifecycle. That’s how NgRx actions work.
In NGXS, you can also catch other lifecycle states in the event stream using filters like ofActionDispatched and ofActionCanceled. These are called Action Handlers. And their syntax is very similar to how an effect would look in NgRx.
@Injectable({ providedIn: 'root' })
export class RouteHandler {
constructor(private router: Router, private actions$: Actions) {
this.actions$
.pipe(ofActionDispatched(RouteNavigate))
.subscribe(({ payload }) => this.router.navigate([payload]));
}
}
The missing switchMap
Our NgRx effect had a switchMap.
We use switchMap to make HTTP Observable handling more convenient. When a loadDataRequest is in progress, and a new such event arrives, switchMap will unsubscribe from the previous HTTP call’s observable and initiate a new request. Essentially, canceling the earlier one. This ensures the dataLoadSucceeded event will fire with the latest completed HTTP request’s data. This is a bit of a lifecycle management inside the effect; however, you can’t get any information about the cancellation. You could code it up yourself, but NgRx does not support this out of the box. And it probably never will, as it goes against the paradigm of separating the dispatchers and the handlers completely.
In NGXS, this is built in; see the docs here. You can add a cancelUncompleted parameter to the action decorator, and it will make sure not to complete the command’s observable if a new action has been dispatched. You can also use RxJS operators for more advanced use cases to have fine-grained control over the returned observable behavior. Since this is out-of-scope for NgRx, it provides no APIs for such use cases. You can achieve this but must design your actions and effects differently.
// load data effect
createEffect(() => {
return this.actions$.pipe(
ofType(loadDataRequest),
switchMap(({ dataId }) =>
this.dataService.loadData(dataId).pipe(
map((res) => dataLoadSucceeded({ data: res.data }))
)
)
);
});
Speaking of designing your architecture, it is about time we hit action-scoping questions.
Scoping actions
By now, you should understand how the two frameworks approach problems differently. Where all these come together is the design of actions.
It’s time to address questions like:
- When and how does your application change?
- How many actions will you have?
- What are these actions?
- What is going to be the responsibility of each handler? Effect? Reducer?
- What are your non-pure side effects? Like navigation, HTTP calls?
There is an excellent talk on Good Action Hygiene for NgRx. It can also be used for NGXS; however, it deals with actions as events NOT as commands. Since NgRx prescribes an architecture and adheres to strict rules, it is straightforward to go through and identify all your actions. This might feel strange at first, but it’ll become second nature after some practice. You will start thinking about events, effects, and reducers.
With NGXS, your task is both easier and more challenging. Commands are a more natural way of thinking; therefore, it comes easier, but no prescribed architecture exists. It doesn’t tell you when to split an action into multiple sub-actions. There is very little guidance on this front, mainly because the answer is “it depends”. Either way would work, and you have to make the decision. You could take the one extreme and use NGXS as you would use NgRx, split everything, and try to use pure state handler methods. This grants you benefits, but the simplicity you got with NGXS melts away. The other extreme is also unadvisable to keep everything as close as possible and make your state handlers fat. You would lose much visibility, and testing would be very inconvenient.
Another question you’ll need to consistently deal with is when and how to utilize the Action Handlers and the action lifecycle feature. Should you dispatch an action at the end of your state method, or should you subscribe to the observable in the component that you get from dispatch? Again, it’s flexible, and the answer depends on your use case.
You can take shortcuts with NGXS in many places, but it’s up to you to decide. There is little guidance for this in the docs. If you work in a team where everyone has the same mindset and makes the same decisions, this can work very well. You could also create such a team by outlining principles for making these decisions. Either way, with flexibility comes responsibility.
Tradeoffs and the cost of flexibility
If you have made it this far, you should clearly understand the differences. This last section summarizes this.
The primary difference between NGXS and NgRx is the way they prefer to model actions. NGXS uses commands, whereas NgRx is event-based. Commands can include multiple state changes and multiple async calls. It’s a natural way of writing code, and those unfamiliar with functional programming practices might prefer it very much. Commands have a lifecycle, and you can react to lifecycle events. Events have no lifecycle and are fire and forget. The handlers and the dispatchers are completely separated.
NgRx prescribes an architecture and follows strict Redux practices, while NGXS alters some of these to make it more user-friendly. NgRx is very explicit, which might come across as needing to write a lot of boilerplate. NGXS allows you to take a more developer-centric approach by having a State class with @Action decorated methods instead of Effects and Reducers. It also approaches state management more Angularly, providing classes and decorators instead of factory functions. NGXS is generally considered less complex. The action handlers in state methods can return an Observable, allowing the caller to listen for the dispatched command’s lifecycle events.
Both libraries provide great developer tools and plugins; however, NGXS is a bit behind, as the DevTools can’t pick up multiple state changes within a single command. It will only register the last one. Unfortunately, using the provided state logger does not eliminate this problem; however, you can code this yourself using lifecycle callbacks. NgRx excels on this front, as the state only changes after an action is dispatched. DevTools picks it up very nicely.
NGXS gives you more flexibility and responsibility to handle your options consistently across features and your team. NgRx, due to its perceived complexity, has a steeper learning curve and gives you a strict toolset to work with. With NgRx, there is no room for deviation; your hands are tied (in a good way).
It all depends
We have reached the end of our discussion; it’s time to share my thought process in choosing. I chose NgRx for my project, and here’s why.
NgRx closely adheres to the pattern that Redux prescribes. It’s very explicit and forces you into an architectural design that’s easy to test and mandates separation of concerns. I am a fan of functional programming paradigms, which allow you to easily reason about your code’s correctness. I also work in a team and welcome the fact that lots of questions are pre-answered by the framework. There is one correct way of doing things. I don’t have to think about the options NGXS would provide. I would have given NGXS more thought if it had a style guide like Redux’s.
After a bit of practice, I found it easy to think about reducers and effects. I actually got to the point of inventing RxLang 😎. You can pass a simple bullet-point style feature definition to GPT4 to generate all the “boilerplate”. Of course, the thinking has to happen before. An AI companion can help with that as well.
Here is a snippet for the login flow.
You are an NgRx, Angular, and Typescript expert. You are a 10x developer, writing clean code and applying best practices. Help me write the NgRx reducers, actions, selectors, and effects based on the pseudocode and descriptions I provide. For the reducers, use the `immer` library for patching the immutable state. The scope is user authentication. Ask questions and clarify if needed. Only return the code and/or your questions. No explanation is necessary. Take a deep breath and work on this problem step-by-step. This is very important to my career.
## state
- auth: AuthState
- user?: User
- name: string
- token?: string
- state: AuthStateEnum
- Anonymous
- SendingMagicLink
- MagicLinkSent
- Authenticating
- Authenticated
- error?: string
## actions
- [Login Page] Request Magic Link (email: string)
- reduce
- if state == Anonymous
- state = SendingMagicLink
- effect
- ApiClient.requestMagicLink(email)
- ok
- > [Auth API] Magic Link Request Succeeded
- error
- > [Auth API] Magic Link Request Failed (error)
- [Auth API] Magic Link Request Succeeded
- reduce
- if state == SendingMagicLink
- state = MagicLinkSent
- [Auth API] Magic Link Request Failed (error: string)
- reduce
- if state == SendingMagicLink
- state = Anonymous
- error = error
...
- [Auth API] Authentication Succeeded (token: string, user: User(name: string))
- reduce
- if state == Authenticating
- state = Authenticated
- set token, user
- effect
- navigate to "/certificates"
...
# selectors
- state
- state.state
- isInLoginFlow
- state is Anonymous or SendingMagickLink
- magicLinkSent
- state is MagicLinkSentAnd guess what?! GPT4 can generate the test cases as well. Most of these implementations are dead simple, with only a few lines of code. Having to write this in NGXS raises questions. You could go full NgRx style using NGXS syntax. If, however, you want to embrace NGXS, there are a lot of questions you need to answer. Where do I do navigation? Should I depend on the Observable returned from dispatch? What’s my action granularity? How many do I need? And most importantly, what are the best practices for these use cases?
These are not trivial to answer. Consider that NGXS allows you to patch the State multiple times in a single method. What stops you from implementing the full login flow in a single method? What should stop you? The answer is probably nothing; how you do it with NGXS is up to you. It’s a lot more flexible.
While building the login flow, I had very similar questions. I couldn’t find clear answers, so I slowly turned towards NgRx, which, with all its strictness, provides clear-cut answers. It forces helps you to stay on course. My NGXS code was easier to digest, especially for untrained eyes. However, in a code setting, I greatly value strictness, explicitness, and testing.
Both choices are great; I asked GPT4 to describe these frameworks as if they were programmers.
NgRx is like a highly disciplined, organized, and robust programmer who’s rigorous in following coding principles and patterns, often writing verbose but structured code. They ensure predictability and maintainability, which is particularly suitable for complex, large-scale projects.
NGXS, on the other hand, would be seen as a pragmatic, efficient, and versatile programmer who prefers simplicity and minimalism. They value intuitive, easy-to-follow code and can get straightforward jobs done quickly, better suited for small to medium-sized tasks.
Pretty good 👍
Thanks for reading, and choose wisely!
Leave a Reply